Variatie en variatiereeksen, reikwijdte van variatie. V. Variatiereeksen, gemiddelde waarden, variabiliteit van eigenschappen
Variatiereeksen - een reeks waarin wordt vergeleken (op basis van de mate van toename of afname) opties en corresponderend frequenties
Opties zijn individuele kwantitatieve uitdrukkingen van een kenmerk. Aangegeven door een Latijnse letter V . Het klassieke begrip van de term ‘variant’ gaat ervan uit dat elke unieke waarde van een kenmerk een variant wordt genoemd, zonder rekening te houden met het aantal herhalingen.
In de variatiereeks van systolische bloeddrukindicatoren gemeten bij tien patiënten:
110, 120, 120, 130, 130, 130, 140, 140, 160, 170;
Er zijn slechts 6 waarden beschikbaar:
110, 120, 130, 140, 160, 170.
Frequentie is een getal dat aangeeft hoe vaak een optie wordt herhaald. Aangeduid met een Latijnse letter P . De som van alle frequenties (die uiteraard gelijk is aan het aantal van alle bestudeerde frequenties) wordt aangegeven als N.
- In ons voorbeeld zullen de frequenties de volgende waarden aannemen:
- voor optie 110 frequentie P = 1 (waarde 110 komt voor bij één patiënt),
- voor optie 120 frequentie P = 2 (waarde 120 komt voor bij twee patiënten),
- voor optie 130 frequentie P = 3 (waarde 130 komt voor bij drie patiënten),
- voor optie 140 frequentie P = 2 (waarde 140 komt voor bij twee patiënten),
- voor optie 160 frequentie P = 1 (waarde 160 komt voor bij één patiënt),
- voor optie 170 frequentie P = 1 (waarde 170 komt voor bij één patiënt),
Soorten variatiereeksen:
- eenvoudig- dit is een reeks waarin elke optie slechts één keer voorkomt (alle frequenties zijn gelijk aan 1);
- opgeschort- een serie waarin één of meerdere opties meerdere keren voorkomen.
De variatiereeks wordt gebruikt om grote reeksen getallen te beschrijven; het is in deze vorm dat de verzamelde gegevens van de meeste medische onderzoeken aanvankelijk worden gepresenteerd. Om de variatiereeksen te karakteriseren, worden speciale indicatoren berekend, waaronder gemiddelde waarden, indicatoren van variabiliteit (de zogenaamde spreiding) en indicatoren van de representativiteit van steekproefgegevens.
Indicatoren voor variatiereeksen
1) Het rekenkundig gemiddelde is een algemene indicator die de omvang van het onderzochte kenmerk karakteriseert. Het rekenkundig gemiddelde wordt aangegeven als M , is het meest voorkomende type gemiddelde. Het rekenkundig gemiddelde wordt berekend als de verhouding van de som van de indicatorwaarden van alle observatie-eenheden tot het aantal bestudeerde onderwerpen. De methode voor het berekenen van het rekenkundig gemiddelde verschilt voor een eenvoudige en gewogen variatiereeks.
Formule voor berekening eenvoudig rekenkundig gemiddelde:
Formule voor berekening gewogen rekenkundig gemiddelde:
M = Σ(V * P)/ n
2) Modus is een andere gemiddelde waarde van de variatiereeks, die overeenkomt met de meest herhaalde optie. Of anders gezegd: dit is de optie die overeenkomt met de hoogste frequentie. Aangeduid als ma . De modus wordt alleen berekend voor gewogen reeksen, omdat in eenvoudige reeksen geen van de opties wordt herhaald en alle frequenties gelijk zijn aan één.
In de variatiereeks van hartslagwaarden bijvoorbeeld:
80, 84, 84, 86, 86, 86, 90, 94;
de moduswaarde is 86, aangezien deze optie 3 keer voorkomt en daarom de frequentie het hoogst is.
3) Mediaan - de waarde van de optie die de variatiereeks in tweeën deelt: aan beide zijden ervan is er een gelijk aantal opties. De mediaan verwijst, net als het rekenkundig gemiddelde en de modus, naar gemiddelde waarden. Aangeduid als Mij
4) Standaardafwijking (synoniemen: standaardafwijking, sigma-afwijking, sigma) - een maatstaf voor de variabiliteit van de variatiereeks. Het is een integrale indicator die alle gevallen van afwijking van het gemiddelde combineert. In feite beantwoordt het de vraag: hoe ver en hoe vaak varianten zich verspreiden vanaf het rekenkundig gemiddelde. Aangeduid met een Griekse letter σ ("sigma").
Als de populatiegrootte meer dan 30 eenheden bedraagt, wordt de standaardafwijking berekend met behulp van de volgende formule:
Voor kleine populaties – 30 observatie-eenheden of minder – wordt de standaardafwijking berekend met een andere formule:
Variatie bepaalt verschillen in de waarden van een kenmerk tussen verschillende eenheden van een bepaalde populatie in dezelfde periode (tijdstip). Variatie wordt veroorzaakt door verschillende bestaansomstandigheden van verschillende eenheden van de bevolking. Zelfs tweelingen verwerven bijvoorbeeld in de loop van hun leven verschillen in lengte en gewicht, maar ook in kenmerken als opleidingsniveau, inkomen, aantal kinderen, enz.
Variatie ontstaat als gevolg van het feit dat de waarden van het attribuut zelf worden gevormd onder de totale invloed van verschillende omstandigheden, die in elk afzonderlijk geval op verschillende manieren worden gecombineerd. De waarde van elke optie is dus objectief.
Variatie is kenmerkend op alle verschijnselen van de natuur en de samenleving, zonder uitzondering, met uitzondering van de wettelijk vastgelegde normatieve betekenissen van individuele sociale kenmerken. Studies naar variatie in de statistiek zijn van groot belang; ze helpen de essentie van het bestudeerde fenomeen te begrijpen. Het vinden van variatie, het achterhalen van de oorzaken ervan, het identificeren van de invloed van individuele factoren leveren belangrijke informatie op voor de implementatie van wetenschappelijk onderbouwde managementbeslissingen.
De gemiddelde waarde geeft een algemeen kenmerk van het kenmerk van de bevolking weer, maar onthult niet de structuur ervan. De gemiddelde waarde laat niet zien hoe de varianten van het gemiddelde kenmerk zich daaromheen bevinden, of ze nu dichtbij het gemiddelde verdeeld zijn of ervan afwijken. Het gemiddelde in twee populaties kan hetzelfde zijn, maar in de ene versie verschillen alle individuele waarden er onbeduidend van, en in de andere zijn deze verschillen groot, d.w.z. in het eerste geval is de variatie van het kenmerk klein, en in het tweede geval is deze groot; dit is erg belangrijk voor het karakteriseren van de betekenis van de gemiddelde waarde.
Om ervoor te zorgen dat het hoofd van een organisatie, een manager of een onderzoeker variatie kan bestuderen en beheren, heeft de statistiek speciale methoden ontwikkeld om variatie te bestuderen (een systeem van indicatoren). Met hun hulp wordt variatie gevonden en worden de eigenschappen ervan gekarakteriseerd. Variatie-indicatoren omvatten : variatiebereik, gemiddelde lineaire afwijking, variatiecoëfficiënt.
Variatieseries en zijn vormen
Variatie serie- dit is een geordende verdeling van eenheden van een populatie, vaak volgens toenemende (minder vaak afnemende) waarden van een kenmerk en het tellen van het aantal eenheden met een bepaalde waarde van het kenmerk. Wanneer het aantal bevolkingseenheden groot is, wordt de gerangschikte reeks omslachtig en duurt de constructie ervan lang. In een dergelijke situatie wordt een variatiereeks geconstrueerd door populatie-eenheden te groeperen op basis van de waarden van het onderzochte kenmerk.
Er zijn de volgende variatiereeksvormen :
- Gerangschikte serie vertegenwoordigt een lijst van individuele eenheden van de populatie in oplopende (aflopende) volgorde van het kenmerk dat wordt bestudeerd.
- Discrete variatiereeks - dit is een tabel bestaande uit twee lijnen of grafieken: specifieke waarden van het variërende kenmerk x en het aantal eenheden van de populatie met een bepaalde waarde f - het frequentiekenmerk. Het wordt geconstrueerd wanneer het attribuut het grootste aantal waarden aanneemt.
- Interval serie.
Het variatiebereik wordt bepaald als de absolute waarde van het verschil tussen de maximale en minimale waarden (varianten) van het kenmerk:
Het scala aan variaties wordt getoond alleen extreme afwijkingen van het kenmerk en weerspiegelt niet de individuele afwijkingen van alle opties in de serie. Het karakteriseert de grenzen van verandering in een variërend kenmerk en is afhankelijk van fluctuaties van twee extreme opties en is absoluut niet gerelateerd aan de frequenties in de variatiereeks, dat wil zeggen aan de aard van de verdeling, die deze waarde een willekeurig karakter geeft. Om variatie te analyseren heb je een indicator nodig die alle fluctuaties in het variatiekenmerk weergeeft en een algemeen kenmerk geeft. De eenvoudigste indicator van dit type is de gemiddelde lineaire afwijking.
Variatie serie is een reeks numerieke waarden van een kenmerk.
De belangrijkste kenmerken van de variatiereeks: v – variant, p – frequentie van voorkomen.
Soorten variatiereeksen:
afhankelijk van de frequentie waarmee de opties voorkomen: eenvoudig - de optie komt één keer voor, gewogen - de optie komt twee of meer keer voor;
op locatie van opties: gerangschikt - opties zijn gerangschikt in aflopende en oplopende volgorde, niet-gerangschikt - opties worden in willekeurige volgorde geschreven;
door een optie in groepen te combineren: gegroepeerd - opties worden gecombineerd in groepen, niet-gegroepeerd - opties worden niet gecombineerd in groepen;
opties op grootte: continu - opties worden uitgedrukt als een geheel getal en een gebroken getal, discreet - opties worden uitgedrukt als een geheel getal, complex - opties worden weergegeven door een relatieve of gemiddelde waarde.
Voor het berekenen van gemiddelde waarden wordt een variatiereeks samengesteld en geformaliseerd.
Variatieserie opnamevorm:
8. Gemiddelde waarden, typen, rekenmethoden, toepassing in de zorg
Gemiddelde waarden– een cumulatief generaliserend kenmerk van kwantitatieve kenmerken. Toepassing van gemiddelden:
1. De organisatie van het werk van medische instellingen karakteriseren en hun activiteiten evalueren:
a) in de kliniek: indicatoren van de werkdruk van artsen, gemiddeld aantal bezoeken, gemiddeld aantal bewoners in het gebied;
b) in een ziekenhuis: het gemiddelde aantal dagen dat een bed per jaar open is; gemiddelde duur van het ziekenhuisverblijf;
c) in het centrum van hygiëne, epidemiologie en volksgezondheid: gemiddelde oppervlakte (of kubieke capaciteit) per persoon, gemiddelde voedingsnormen (eiwitten, vetten, koolhydraten, vitamines, minerale zouten, calorieën), hygiënische normen en standaarden, enz.;
2. Karakteriseren van de fysieke ontwikkeling (belangrijkste antropometrische kenmerken, morfologisch en functioneel);
3. Het bepalen van de medische en fysiologische parameters van het lichaam onder normale en pathologische omstandigheden in klinische en experimentele onderzoeken.
4. In bijzonder wetenschappelijk onderzoek.
Het verschil tussen gemiddelde waarden en indicatoren:
1. Coëfficiënten karakteriseren een alternatief kenmerk dat alleen voorkomt in een bepaald deel van de statistische populatie, en dat al dan niet voorkomt.
Gemiddelde waarden omvatten kenmerken die alle leden van het team gemeen hebben, maar in verschillende mate (gewicht, lengte, dagen behandeling in het ziekenhuis).
2. Coëfficiënten worden gebruikt om kwalitatieve kenmerken te meten. Gemiddelde waarden – voor variërende kwantitatieve kenmerken.
Soorten gemiddelden:
rekenkundig gemiddelde, de kenmerken ervan zijn standaarddeviatie en gemiddelde fout
modus en mediaan. Mode (ma)– komt overeen met de waarde van het kenmerk dat vaker voorkomt dan andere in een bepaalde populatie. Mediaan (ik)– de waarde van een kenmerk dat de mediaanwaarde in een bepaalde populatie inneemt. Het verdeelt de reeks in 2 gelijke delen, afhankelijk van het aantal waarnemingen. Rekenkundig gemiddelde (M)– in tegenstelling tot de modus en de mediaan is deze gebaseerd op alle gedane waarnemingen en is daarom een belangrijk kenmerk voor de gehele verdeling.
andere soorten gemiddelden die in speciale onderzoeken worden gebruikt: wortelgemiddelde kwadratisch, kubisch, harmonisch, geometrisch, progressief.
Rekenkundig gemiddelde karakteriseert het gemiddelde niveau van de statistische populatie.
Voor een eenvoudige serie, waar
∑v – bedragoptie,
n – aantal waarnemingen.
 voor een gewogen reeks, waar
voor een gewogen reeks, waar
∑vр – de som van de producten van elke optie en de frequentie waarmee deze voorkomt
n – aantal waarnemingen.
Standaardafwijking rekenkundig gemiddelde of sigma (σ) karakteriseert de diversiteit van een kenmerk
 - voor een eenvoudige rij
- voor een eenvoudige rij
Σd 2 – de som van de kwadraten van het verschil tussen het rekenkundig gemiddelde en elke optie (d = │M-V│)
n – aantal waarnemingen
 - voor een gewogen rij
- voor een gewogen rij
∑d 2 p – de som van de producten van de kwadraten van het verschil tussen het rekenkundig gemiddelde en elke optie en de frequentie waarmee deze voorkomt,
n – aantal waarnemingen.
De mate van diversiteit kan worden beoordeeld aan de hand van de grootte van de variatiecoëfficiënt  . Meer dan 20% is sterke diversiteit, 10-20% is gemiddelde diversiteit, minder dan 10% is zwakke diversiteit.
. Meer dan 20% is sterke diversiteit, 10-20% is gemiddelde diversiteit, minder dan 10% is zwakke diversiteit.
Als we één sigma (M ± 1σ) optellen en aftrekken bij de rekenkundig gemiddelde waarde, dan zal bij een normale verdeling minstens 68,3% van alle varianten (waarnemingen) binnen deze grenzen vallen, wat wordt beschouwd als de norm voor het fenomeen dat wordt bestudeerd. . Als k 2 ± 2σ, dan zal 95,5% van alle waarnemingen binnen deze grenzen vallen, en als k M ± 3σ, dan zal 99,7% van alle waarnemingen binnen deze grenzen vallen. De standaarddeviatie is dus een standaarddeviatie die ons in staat stelt de waarschijnlijkheid te voorspellen van het voorkomen van een dergelijke waarde van het onderzochte kenmerk dat binnen de gespecificeerde grenzen ligt.
Gemiddelde fout van het rekenkundig gemiddelde of representativiteitsbias. Voor een eenvoudige, gewogen reeks en de regel van momenten:
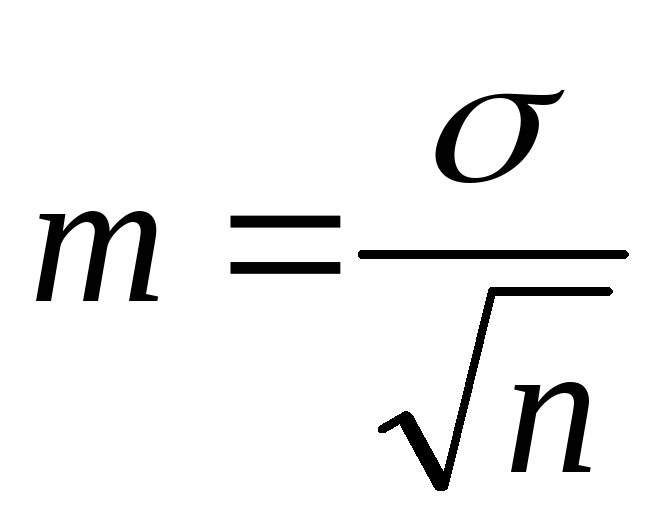 .
.
Om de gemiddelde waarden te berekenen is het noodzakelijk: homogeniteit van het materiaal, een voldoende aantal waarnemingen. Als het aantal waarnemingen kleiner is dan 30, wordt n-1 gebruikt in de formules voor het berekenen van σ en m.
Bij het beoordelen van het resultaat dat wordt verkregen door de grootte van de gemiddelde fout, wordt een betrouwbaarheidscoëfficiënt gebruikt, die het mogelijk maakt de waarschijnlijkheid van een juist antwoord te bepalen, dat wil zeggen dat het aangeeft dat de resulterende waarde van de steekproeffout niet groter zal zijn dan de daadwerkelijke fout die is gemaakt als gevolg van voortdurende observatie. Bijgevolg neemt bij een toename van de bede breedte van het betrouwbaarheidsinterval toe, wat op zijn beurt het vertrouwen van het oordeel en de draagbaarheid van het verkregen resultaat vergroot.
Statistische distributiereeksen– dit is een geordende verdeling van bevolkingseenheden in groepen volgens een bepaald variërend kenmerk.Afhankelijk van het kenmerk dat ten grondslag ligt aan de vorming van de distributiereeksen, zijn er attributieve en gevarieerde distributiereeksen.
De aanwezigheid van een gemeenschappelijk kenmerk vormt de basis voor de vorming van een statistische populatie, die de resultaten vertegenwoordigt van het beschrijven of meten van de algemene kenmerken van de studieobjecten.
Het onderwerp van studie in de statistiek is veranderende (variërende) kenmerken of statistische kenmerken.
Soorten statistische kenmerken.
Verdelingsreeksen worden attributief genoemd gebouwd volgens kwaliteitscriteria. Attributief– dit is een bord met een naam (bijvoorbeeld beroep: naaister, onderwijzeres, enz.).
De distributiereeksen worden doorgaans gepresenteerd in de vorm van tabellen. In tafel 2.8 toont de attribuutverdelingsreeksen.
Tabel 2.8 - Verdeling van de soorten rechtsbijstand die door advocaten worden verleend aan burgers van een van de regio's van de Russische Federatie.
Variatiereeksen zijn distributiereeksen, gebouwd op kwantitatieve basis. Elke variatiereeks bestaat uit twee elementen: opties en frequenties.
Varianten worden beschouwd als de individuele waarden van een kenmerk die in een variatiereeks voorkomen.
Frequenties zijn de aantallen individuele varianten of elke groep van een variatiereeks, d.w.z. Dit zijn cijfers die laten zien hoe vaak bepaalde opties voorkomen in een distributiereeks. De som van alle frequenties bepaalt de omvang van de gehele populatie, het volume.
Frequenties zijn frequenties uitgedrukt als fracties van een eenheid of als percentage van het totaal. Dienovereenkomstig is de som van de frequenties gelijk aan 1 of 100%. Met de variatiereeksen kan men de vorm van de verdelingswet schatten op basis van feitelijke gegevens.
Afhankelijk van de aard van de variatie van de eigenschap, zijn er discrete en intervalvariatiereeksen.
Een voorbeeld van een discrete variatiereeks wordt gegeven in de tabel. 2.9.
Tabel 2.9 - Verdeling van gezinnen naar het aantal bezette kamers in individuele appartementen in 1989 in de Russische Federatie.
Variatie serie
Een bepaald kwantitatief kenmerk wordt bestudeerd in de algemene bevolking. Hieruit wordt willekeurig een volumemonster gehaald N, dat wil zeggen dat het aantal monsterelementen gelijk is aan N. In de eerste fase van de statistische verwerking variërend monsters, d.w.z. nummer bestellen x 1 , x 2 , …, x n Oplopend. Elke waargenomen waarde x ik genaamd keuze. Frequentie ik ik is het aantal waarnemingen van de waarde x ik in het monster. Relatieve frequentie (frequentie) w ik is de frequentieverhouding ik ik naar de steekproefomvang N: .Bij het bestuderen van variatiereeksen worden ook de concepten van geaccumuleerde frequentie en geaccumuleerde frequentie gebruikt. Laten X een aantal. Dan het aantal opties , waarvan de waarden lager zijn X, wordt de geaccumuleerde frequentie genoemd: voor x i
Een kenmerk wordt discreet variabel genoemd als de individuele waarden (varianten) van elkaar verschillen met een bepaalde eindige waarde (meestal een geheel getal). De variatiereeks van een dergelijk kenmerk wordt een discrete variatiereeks genoemd.
Tabel 1. Algemeen beeld van een reeks discrete variatiefrequenties
| Karakteristieke waarden | x ik | x 1 | x 2 | … | x n |
| Frequenties | ik ik | m 1 | m2 | … | m n |
Een kenmerk wordt continu variërend genoemd als de waarden ervan een willekeurig klein bedrag van elkaar verschillen, d.w.z. het attribuut kan binnen een bepaald interval elke waarde aannemen. Een continue variatiereeks voor een dergelijke karakteristiek wordt interval genoemd.
Tabel 2. Algemeen overzicht van de intervalvariatiereeksen van frequenties
Tabel 3. Grafische afbeeldingen van de variatiereeks
| Rij | Veelhoek of histogram | Empirische distributiefunctie | |
| Discreet |  |  |  |
| Interval |  |  |  |
Voor de grafische weergave van variatiereeksen zijn de meest gebruikte polygoon, histogram, cumulatieve curve en empirische verdelingsfunctie.
In tafel 2.3 (Groepering van de Russische bevolking naar gemiddeld inkomen per hoofd van de bevolking in april 1994) wordt gepresenteerd intervalvariatiereeks.
Het is handig om distributiereeksen te analyseren met behulp van een grafisch beeld, waarmee u de vorm van de distributie kunt beoordelen. Een visuele weergave van de aard van veranderingen in de frequenties van de variatiereeksen wordt gegeven door veelhoek en histogram.
De polygoon wordt gebruikt bij het weergeven van discrete variatiereeksen.
Laten we bijvoorbeeld de verdeling van de woningvoorraad naar type appartement grafisch weergeven (Tabel 2.10).
Tabel 2.10 - Verdeling van de woningvoorraad van het stedelijk gebied naar type appartement (voorwaardelijke cijfers).

Rijst. Woningverdeelgebied
Op de ordinaatassen kunnen niet alleen de frequentiewaarden, maar ook de frequenties van de variatiereeksen worden uitgezet.
Het histogram wordt gebruikt om een intervalvariatiereeks weer te geven. Bij het construeren van een histogram worden de waarden van de intervallen op de abscis-as uitgezet en worden de frequenties weergegeven door rechthoeken die op de overeenkomstige intervallen zijn gebouwd. De hoogte van de kolommen bij gelijke intervallen moet evenredig zijn met de frequenties. Een histogram is een grafiek waarin een reeks wordt weergegeven als naast elkaar gelegen balken.
Laten we de intervalverdelingsreeksen uit de tabel grafisch weergeven. 2.11.
Tabel 2.11 - Verdeling van gezinnen naar omvang van de woonruimte per persoon (voorwaardelijke cijfers).
| N p/p | Groepen gezinnen naar grootte van de woonruimte per persoon | Aantal gezinnen met een bepaalde woonoppervlakte | Cumulatief aantal gezinnen |
| 1 | 3 – 5 | 10 | 10 |
| 2 | 5 – 7 | 20 | 30 |
| 3 | 7 – 9 | 40 | 70 |
| 4 | 9 – 11 | 30 | 100 |
| 5 | 11 – 13 | 15 | 115 |
| TOTAAL | 115 | ---- | |

Rijst. 2.2. Histogram van de verdeling van gezinnen naar de grootte van de woonruimte per persoon
Met behulp van de gegevens van de verzamelde reeksen (Tabel 2.11) construeren we cumuleren van de distributie.

Rijst. 2.3. Cumulatieve verdeling van gezinnen naar grootte van de woonruimte per persoon
De weergave van een variatiereeks in de vorm van een cumulatief is vooral effectief voor variatiereeksen waarvan de frequenties worden uitgedrukt als fracties of percentages van de som van de reeksfrequenties.
Als we de assen veranderen bij het grafisch weergeven van een variatiereeks in de vorm van cumulatieven, dan krijgen we: Ogiva. In afb. 2.4 toont een ogive die is opgebouwd op basis van de gegevens in de tabel. 2.11.
Een histogram kan worden omgezet in een verdelingspolygoon door de middelpunten van de zijden van de rechthoeken te vinden en deze punten vervolgens met rechte lijnen te verbinden. De resulterende verdelingspolygoon wordt getoond in Fig. 2.2 met een stippellijn.
Bij het construeren van een histogram van de verdeling van een variatiereeks met ongelijke intervallen, zijn het niet de frequenties die langs de ordinaat worden uitgezet, maar de distributiedichtheid van de karakteristiek in de overeenkomstige intervallen.
De distributiedichtheid is de frequentie berekend per eenheidsintervalbreedte, d.w.z. hoeveel eenheden in elke groep er zijn per eenheid van intervalwaarde. Een voorbeeld van het berekenen van de distributiedichtheid wordt weergegeven in de tabel. 2.12.
Tabel 2.12 - Verdeling van bedrijven naar aantal werknemers (voorwaardelijke cijfers)
| N p/p | Groepen ondernemingen op basis van aantal werknemers, mensen. | Aantal ondernemingen | Intervalgrootte, mensen. | Distributiedichtheid |
| A | 1 | 2 | 3=1/2 | |
| 1 | Tot 20 | 15 | 20 | 0,75 |
| 2 | 20 – 80 | 27 | 60 | 0,25 |
| 3 | 80 – 150 | 35 | 70 | 0,5 |
| 4 | 150 – 300 | 60 | 150 | 0,4 |
| 5 | 300 – 500 | 10 | 200 | 0,05 |
| TOTAAL | 147 | ---- | ---- |
Kan ook worden gebruikt om variatiereeksen grafisch weer te geven cumulatieve curve. Met behulp van een cumulatieve (somcurve) wordt een reeks geaccumuleerde frequenties weergegeven. Cumulatieve frequenties worden bepaald door frequenties over groepen opeenvolgend op te tellen en laten zien hoeveel eenheden in de populatie attribuutwaarden hebben die niet groter zijn dan de waarde in kwestie.

Rijst. 2.4. Ogive van de verdeling van gezinnen naar de grootte van de woonruimte per persoon
Bij het construeren van de cumulaties van een intervalvariatiereeks worden varianten van de reeks uitgezet langs de abscis-as, en worden de geaccumuleerde frequenties uitgezet langs de ordinaat-as.
Variatie serie - dit is een statistische reeks die de verdeling van het onderzochte fenomeen weergeeft op basis van de waarde van elk kwantitatief kenmerk. Bijvoorbeeld patiënten naar leeftijd, duur van de behandeling, pasgeborenen naar gewicht, enz.
Keuze - individuele waarden van het kenmerk waarmee de groepering wordt uitgevoerd (aangeduid V ) .
Frequentie- een getal dat aangeeft hoe vaak een bepaalde optie voorkomt (aangeduid P ) . De som van alle frequenties wordt weergegeven totaal aantal waarnemingen en wordt aangewezen N . Het verschil tussen de grootste en de kleinste variant van een variatiereeks wordt genoemd bereik of amplitude .
Er zijn variatieseries:
1. Discontinu (discreet) en continu.
Een reeks wordt als continu beschouwd als het groeperingskenmerk in fractionele hoeveelheden kan worden uitgedrukt (gewicht, lengte, enz.), en als discontinu als het groeperingskenmerk alleen als een geheel getal kan worden uitgedrukt (dagen van invaliditeit, aantal hartslagen, enz.).
2. Eenvoudig en evenwichtig.
Een eenvoudige variatiereeks is een reeks waarin de kwantitatieve waarde van een variërend kenmerk één keer voorkomt. Bij een gewogen variatiereeks worden de kwantitatieve waarden van een variërend kenmerk met een bepaalde frequentie herhaald.
3. Gegroepeerd (interval) en niet-gegroepeerd.
Bij een gegroepeerde serie zijn opties gecombineerd in groepen die ze binnen een bepaald interval op grootte verenigen. In een niet-gegroepeerde reeks komt elke individuele optie overeen met een bepaalde frequentie.
4. Even en oneven.
Bij even variatiereeksen wordt de som van de frequenties of het totale aantal waarnemingen uitgedrukt door een even getal, bij oneven door een oneven getal.
5. Symmetrisch en asymmetrisch.
In een symmetrische variatiereeks vallen alle soorten gemiddelde waarden samen of liggen ze heel dichtbij (modus, mediaan, rekenkundig gemiddelde).
Afhankelijk van de aard van de fenomenen die worden bestudeerd, van de specifieke taken en doelstellingen van statistisch onderzoek, evenals van de inhoud van het bronnenmateriaal, in sanitaire statistieken De volgende typen gemiddelden worden gebruikt:
structurele middelen (modus, mediaan);
rekenkundig gemiddelde;
harmonisch gemiddelde;
geometrisch gemiddelde;
gemiddeld progressief.
Mode (M O ) - de waarde van een wisselend kenmerk, dat vaker voorkomt in de onderzochte populatie, namelijk: optie die overeenkomt met de hoogste frequentie. Ze vinden het rechtstreeks uit de structuur van de variatiereeks, zonder toevlucht te nemen tot berekeningen. Het is meestal een waarde die heel dicht bij het rekenkundig gemiddelde ligt, wat in de praktijk erg handig is.
Mediaan (M e ) - het verdelen van de variatiereeksen (gerangschikt, d.w.z. de waarden van de optie zijn gerangschikt in oplopende of aflopende volgorde) in twee gelijke helften. De mediaan wordt berekend met behulp van de zogenaamde oneven reeks, die wordt verkregen door opeenvolgende sommatie van frequenties. Als de som van de frequenties overeenkomt met een even getal, wordt gewoonlijk het rekenkundig gemiddelde van de twee gemiddelde waarden als mediaan genomen.
Modus en mediaan worden gebruikt in het geval van een open populatie, d.w.z. wanneer de grootste of kleinste opties geen exact kwantitatief kenmerk hebben (bijvoorbeeld tot 15 jaar, 50 jaar en ouder, enz.). In dit geval kan het rekenkundig gemiddelde (parametrische kenmerken) niet worden berekend.
Gemiddeld Ik ben rekenkundig - de meest voorkomende waarde. Het rekenkundig gemiddelde wordt vaak aangegeven met M.
Er zijn eenvoudige en gewogen rekenkundige gemiddelden.
Eenvoudig rekenkundig gemiddelde berekend:
- in gevallen waarin de populatie wordt vertegenwoordigd door een eenvoudige lijst met kennis over een kenmerk voor elke eenheid;
- als het aantal herhalingen van elke optie niet kan worden bepaald;
- als het aantal herhalingen van elke optie dicht bij elkaar ligt.
Het eenvoudige rekenkundige gemiddelde wordt berekend met behulp van de formule:
waarbij V - individuele waarden van het kenmerk; n - aantal individuele waarden;  - sommatieteken.
- sommatieteken.
Het eenvoudige gemiddelde is dus de verhouding tussen de som van de varianten en het aantal waarnemingen.
Voorbeeld: bepaal de gemiddelde verblijfsduur in een bed voor 10 patiënten met longontsteking:
16 dagen - 1 patiënt; 17–1; 18–1; 19–1; 20–1; 21–1; 22–1; 23–1; 26–1; 31–1.
bed-dag
Rekenkundig gemiddelde gewogen wordt berekend in gevallen waarin individuele waarden van een kenmerk worden herhaald. Het kan op twee manieren worden berekend:
1. Direct (rekenkundig gemiddelde of directe methode) volgens de formule:
 ,
,
waarbij P de frequentie (aantal gevallen) van observaties van elke optie is.
Het gewogen rekenkundig gemiddelde is dus de verhouding van de som van de producten van variant en frequentie tot het aantal waarnemingen.
2. Door afwijkingen van het voorwaardelijke gemiddelde te berekenen (met behulp van de momentenmethode).
De basis voor het berekenen van het gewogen rekenkundig gemiddelde is:
– gegroepeerd materiaal volgens varianten van een kwantitatief kenmerk;
— alle opties moeten worden gerangschikt in oplopende of aflopende volgorde van de waarde van het attribuut (gerangschikte reeks).
Om te berekenen met behulp van de momentenmethode is een voorwaarde dat alle intervallen even groot zijn.
Met behulp van de momentenmethode wordt het rekenkundig gemiddelde berekend met behulp van de formule:
 ,
,
waarbij Mo het voorwaardelijke gemiddelde is, dat vaak wordt beschouwd als de waarde van het kenmerk dat overeenkomt met de hoogste frequentie, d.w.z. wat vaker wordt herhaald (Mode).
i is de waarde van het interval.
a is een voorwaardelijke afwijking van de voorwaarden van het gemiddelde, wat een opeenvolgende reeks getallen is (1, 2, enz.) met een + teken voor varianten van grote voorwaardelijke gemiddelden en met een – teken (–1, –2, enz.) .) voor varianten die onder het conventionele gemiddelde liggen. De voorwaardelijke afwijking van de variant die als voorwaardelijk gemiddelde wordt genomen, is 0.
P - frequenties.
 - totaal aantal waarnemingen of n.
- totaal aantal waarnemingen of n.
Voorbeeld: bepaal rechtstreeks de gemiddelde lengte van 8-jarige jongens (tabel 1).
tafel 1
|
Hoogte cm |
jongens p |
Centraal optie V | |
De centrale optie - het midden van het interval - wordt gedefinieerd als de semi-som van de beginwaarden van twee aangrenzende groepen:
 ;
;  enz.
enz.
Het product VP wordt verkregen door de centrale varianten te vermenigvuldigen met de frequenties  ;
; enz. Vervolgens worden de resulterende producten toegevoegd en verkregen
enz. Vervolgens worden de resulterende producten toegevoegd en verkregen  , dat wordt gedeeld door het aantal waarnemingen (100) en er wordt een gewogen rekenkundig gemiddelde verkregen.
, dat wordt gedeeld door het aantal waarnemingen (100) en er wordt een gewogen rekenkundig gemiddelde verkregen.
 cm.
cm.
We zullen hetzelfde probleem oplossen met behulp van de momentenmethode, waarvoor de volgende tabel 2 is samengesteld:
tafel 2
|
Hoogte in cm (V) |
jongens p | ||
n=100 
We nemen 122 als Mo, omdat van de 100 observaties hadden 33 mensen een lengte van 122 cm. We vinden voorwaardelijke afwijkingen (a) van het voorwaardelijke gemiddelde in overeenstemming met het bovenstaande. Vervolgens verkrijgen we het product van voorwaardelijke afwijkingen per frequentie (aP) en vatten we de verkregen waarden samen (  ). Het resultaat is 17. Ten slotte vervangen we de gegevens in de formule:
). Het resultaat is 17. Ten slotte vervangen we de gegevens in de formule:

Bij het bestuderen van een variërend kenmerk kan men zich niet beperken tot het berekenen van alleen gemiddelde waarden. Het is ook noodzakelijk om indicatoren te berekenen die de mate van diversiteit van de onderzochte kenmerken karakteriseren. De waarde van een of ander kwantitatief kenmerk is niet voor alle eenheden van de statistische populatie hetzelfde.
Het kenmerk van een variatiereeks is de standaarddeviatie (  ), die de spreiding (spreiding) van de bestudeerde kenmerken toont ten opzichte van het rekenkundig gemiddelde, d.w.z. karakteriseert de variabiliteit van de variatiereeks. Het kan direct worden bepaald met behulp van de formule:
), die de spreiding (spreiding) van de bestudeerde kenmerken toont ten opzichte van het rekenkundig gemiddelde, d.w.z. karakteriseert de variabiliteit van de variatiereeks. Het kan direct worden bepaald met behulp van de formule:

De standaardafwijking is gelijk aan de wortel van de som van de producten van de kwadratische afwijkingen van elke optie van het rekenkundig gemiddelde (V–M) 2 door de frequenties gedeeld door de som van de frequenties (  ).
).
Rekenvoorbeeld: bepaal het gemiddelde aantal ziekteverlofattesten dat per dag in de kliniek wordt afgegeven (Tabel 3).
tafel 3
|
Aantal ziektedagen bladen uitgegeven dokter per dag (V) |
Aantal artsen (P) | ||||
 ;
; 
In de noemer, wanneer het aantal waarnemingen kleiner is dan 30, is het noodzakelijk vanaf  trek er één af.
trek er één af.
Als de reeks met gelijke intervallen is gegroepeerd, kan de standaardafwijking worden bepaald met behulp van de momentenmethode:
 ,
,
waarbij i de waarde van het interval is;
 - voorwaardelijke afwijking van het voorwaardelijke gemiddelde;
- voorwaardelijke afwijking van het voorwaardelijke gemiddelde;
P - frequentievariant van de overeenkomstige intervallen;
 - totaal aantal waarnemingen.
- totaal aantal waarnemingen.
Voorbeeld berekening : Bepaal de gemiddelde verblijfsduur van patiënten op een therapeutisch bed (met behulp van de momentenmethode) (Tabel 4):
Tabel 4
|
Aantal dagen blijf in bed (V) |
ziek (P) |
|
|
|



 ;
;
De Belgische statisticus A. Quetelet ontdekte dat variaties in massaverschijnselen gehoorzamen aan de wet van de foutenverdeling, die vrijwel gelijktijdig werd ontdekt door K. Gauss en P. Laplace. De curve die deze verdeling weergeeft, heeft de vorm van een bel. Volgens de normale verdelingswet ligt de variabiliteit van individuele waarden van een kenmerk binnen de grenzen  , dat 99,73% van alle eenheden in de bevolking bestrijkt.
, dat 99,73% van alle eenheden in de bevolking bestrijkt.
Er is berekend dat als je 2 optelt en aftrekt van het rekenkundig gemiddelde  , dan valt 95,45% van alle leden van de variatiereeks binnen de verkregen waarden en, ten slotte, als we 1 optellen en aftrekken van het rekenkundig gemiddelde
, dan valt 95,45% van alle leden van de variatiereeks binnen de verkregen waarden en, ten slotte, als we 1 optellen en aftrekken van het rekenkundig gemiddelde  , dan zal 68,27% van alle leden van deze variatiereeks binnen de verkregen waarden vallen. In de geneeskunde met omvang
, dan zal 68,27% van alle leden van deze variatiereeks binnen de verkregen waarden vallen. In de geneeskunde met omvang  1
1 Het concept van norm is verwant. De afwijking van het rekenkundig gemiddelde is meer dan 1
Het concept van norm is verwant. De afwijking van het rekenkundig gemiddelde is meer dan 1  , maar minder dan 2
, maar minder dan 2  is subnormaal en de afwijking is meer dan 2
is subnormaal en de afwijking is meer dan 2  abnormaal (boven of onder normaal).
abnormaal (boven of onder normaal).
In gezondheidsstatistieken wordt de drie-sigmaregel gebruikt bij het bestuderen van de fysieke ontwikkeling, het beoordelen van de prestaties van zorginstellingen en het beoordelen van de gezondheid van de bevolking. Dezelfde regel wordt in de nationale economie veel gebruikt bij het vaststellen van normen.
De standaardafwijking dient dus voor:
— metingen van de spreiding van de variatiereeksen;
— kenmerken van de mate van diversiteit van kenmerken, die worden bepaald door de variatiecoëfficiënt:

Als de variatiecoëfficiënt meer dan 20% is - sterke diversiteit, van 20 tot 10% - gemiddeld, minder dan 10% - zwakke diversiteit aan eigenschappen. De variatiecoëfficiënt is tot op zekere hoogte een criterium voor de betrouwbaarheid van het rekenkundig gemiddelde.